Stop Guessing, Start Knowing: How Real-Time Condition Monitoring Drives Productivity, Minimizes Downtime
Condition monitoring systems and their components contribute to the efficient and trouble-free operation of machines and plants. With them, you know the current status of your machines and can make informed decisions for the future.
Still, many companies continue to use reactive or preventative maintenance approaches, which may incur high spare costs, inefficient use of maintenance resources and, worst of all, significant unplanned downtime. Condition monitoring takes a more proactive approach to maintenance by monitoring equipment conditions for anomalies and sending alarms when thresholds are exceeded.
In short, condition monitoring allows you to increase performance and productivity, reduce costs, optimize processes, and minimize downtime. And condition monitoring is the first step toward true predictive maintenance.
So, where do you start?
- Target the machines that cause you the most frustration or could have the most impact on your production if they fail.
- Consider where, when, and how equipment can fail. Consider your own experience, ask partners with similar machines, or even your equipment supplier to help you determine the most common failure points and modes.
- Analyze which parts of the machine fail. Moving parts have the highest potential failure point. On many machines, these include motors, gearboxes, fans, pumps, bearings, conveyors, and shafts.
- Consider what to measure. Vibration is a commonly gathered measurement and is often assessed in combination with temperature and humidity. On some machines, pressure, flow, or amperage / voltage should be measured.
Which data do you need?
The condition monitoring data you should collect depends on the individual application because different machine components fail in different ways and exhibit different failure indicators. Increased vibration and temperature can be early failure indicators for moving equipment, whereas changes in pressure and flow may be better failure indicators for fluid power systems. Once the appropriate indicators are known, you can select the sensors to best gather that data. These sensors will then transmit the data and allow the controller, supervisory system or cloud to use real-time condition monitoring data with the same speed they use a sensor’s primary process data. While there are others, these four indicators are frequently gathered:
Vibration: A change in vibration can signal an equipment problem, especially for moving components. A vibration sensor can send an alarm when a threshold is exceeded, notifying an operator to quickly check the process or stop the machine, to look for a jam, an equipment problem, or other cause of the vibration. This allows fast, proactive resolution to prevent downtime, scrap, and damage.
Humidity: Monitoring environmental factors such as humidity can provide feedback on issues such as the unwanted presence of water. This is especially important for electronics and in control cabinets. An open enclosure or broken seal can lead to moisture or corrosion damage. A humidity monitor can help detect these conditions, allowing the issue to be addressed before major damage occurs.
Temperature: A significant temperature change can indicate emerging problems. This is especially true for moving components such as bearings, motors, and gearboxes, along with non-moving components such as control panels and sensor electronics. Early detection and tracking of unusual temperature changes enables proactive service or replacement of failing components.
Flow Rate: The flow rate in a lubrication or hydraulic system is critical to system performance. Changes in the flow rate can mean both an immediate drop in machine efficiency and long-term damage. Monitoring these changes allows for issues such as system leaks or dirty filters to be handled proactively before major damage occurs.
Selection of the optimal condition monitoring sensor depends on the equipment being monitored, other attributes being sensed, budget / cost-benefit trade-off, and the maintenance approach. In some cases, a single-purpose, dedicated condition monitoring sensor may be the right choice. In other cases, a multi-function sensor which can handle both condition monitoring and standard sensing tasks may be an efficient and cost-effective solution.
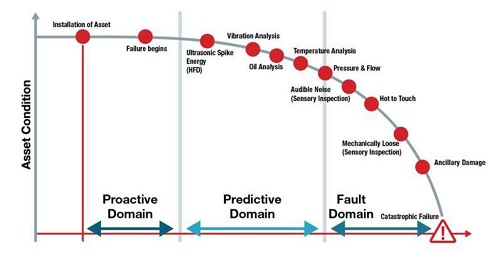
Identify Equipment Failures Before They Occur
The Potential – Functional Failure (P-F) Curve gives a rough picture of when various indicators may emerge during the progression of a failure. It shows the interval between the detection of a potential failure (P) and the occurrence of a functional failure (F). It shows the different stages of an asset’s life, how failures progress, and how and when different symptoms emerge which might signal impending (or actual) failure.
Products and materials wear overtime. Early onset performance degradation is minor and may not require significant action. But, as time progresses, the potential failure indicators become stronger and more easily detectable, and the performance degradation becomes more severe, eventually ending in catastrophic failure. The timeline is split into three domains:
- Proactive domain with activities including designing for reliability, precision installation and alignment, and life cycle asset management.
- Predictive domain in which timely action may be taken to prevent failure or replace failing equipment before catastrophic failure occurs.
- Fault domain when symptoms indicate immediate action is necessary to address occurring or inevitable failure.
During these domains, different indicators / symptoms emerge. Ultrasonic, vibration and oil analysis often signal problems early; then temperature rise, and noises emerge a bit later; and finally, parts come loose, and more severe damage occurs. Depending on the asset, other indicators may be shown by activities including corrosion monitoring, motor current / power analysis and process parameter trending (eg., flows, rates, pressure, temperatures, etc.).
By analyzing which symptoms of failure are likely to appear in the predictive domain for a given piece of equipment, you can determine which failure indicators to prioritize in your own condition monitoring and predictive maintenance discussions.
In general, the goal is to maximize the P-F interval, which is the time between the first symptoms of impending failure and the functional failure taking place. In other words, you want to become aware of an impending failure as soon as possible to allow more time for action. This, however, must be balanced with the cost of the methods of prevention, inspection, and detection.
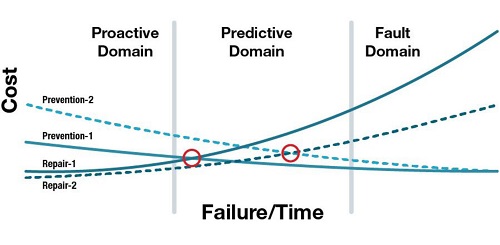
Cost Benefit Trade-offs
There is a trade-off between the cost of systems to detect and predict the failures and how soon you might detect the condition. Generally, the earlier the detection / prediction, the more expensive it is. However, the longer it takes to detect an impending failure (i.e., the more the asset’s condition degrades), and more expensive it is to repair.
Every asset will have a unique trade-off between the cost of failure prevention (detection / prediction) and the cost of failure. This means some assets call for earlier detection methods that come with higher prevention costs like condition monitoring and analytics systems due to the high cost to repair (see the Prevention-1 and Repair-1 curves in the Cost-Failure / Time chart). And some assets may be better suited for more cost-efficient but delayed detection or even a “run-to-failure” model due to lower cost to repair (the Prevention-2 and Repair-2 curves).
There are four basic maintenance approaches:
Reactive: The reactive approach has low or even no cost to implement but can result in a high repair / failure cost because no action is taken until the asset has reached a fault state. This approach might be appropriate when the cost of monitoring systems is very high compared to the cost of repairing or replacing the asset. As a general guideline, the reactive approach is not a good strategy for any critical and / or high value assets due to their high cost of a failure.
Preventative: The preventative approach (maintenance at time-based intervals) may be appropriate when failures are age related and maintenance can be performed at regular intervals before anticipated failures occur. Two drawbacks to this approach are: 1) the cost and time of preventative maintenance can be high; and 2) studies show that only 18% of failures are age related (source: ARC Advisory Group), or that 82% of failures are “random” due to improper design / installation, operator error, quality issues, machine overuse, etc. Taking the preventative approach may be spending time and money on unnecessary work, and it may not prevent expensive failures in critical or high value assets.
Condition Based: The condition-based approach attempts to address failures regardless of whether they are age-based or random. Assets are monitored for one or more potential failure indicators, such as vibration, temperature, current / voltage, pressure, etc. The data is often sent to a PLC local HMI, special processor, or the cloud through an edge gateway. Predefined limits are set and alerts (alarm, operator message, maintenance / repair) are only sent when a limit is reached. This approach avoids unnecessary maintenance and can give warning before a failure occurs. Condition-based monitoring can be very cost-effective, though very sophisticated solutions can be expensive. It is a good solution when the cost of failure is medium or high and known indicators provide a reliable warning of impending failure.
Predictive Analytics: Predictive analytics is the most sophisticated approach and attempts to learn from machine performance to predict failures. It uses data gathered through condition monitoring, and then applies analysis or AI / machine learning to uncover patterns to predict failures. The hardware and software to implement predictive analytics can be expensive, and this method is best for high-value / critical assets and expensive potential failures.
Which Approach is Best for You?
You must evaluate the unique attributes of your assets and decide on the best approach and trade-offs of the cost of prevention (detection of potential failure) against the cost of repair / failure. In general, a reactive approach is only best when the cost of failure is very low. Preventative maintenance may be appropriate when failures are clearly age-related. And advanced approaches, such as condition-based monitoring and predictive analytics are best when the cost of repair or failure is high.
Also, not that technology providers are continually improving condition monitoring and predictive solutions. By lowering condition monitoring system costs and making them easier to setup and use, users can cost-effectively move from reactive or preventative approaches to condition-based or predictive approaches.
What to take a deeper dive into condition monitoring?
Start here to stop guessing and start knowing.